
High-throughput AI-Integrated Antibody Discovery Workflow
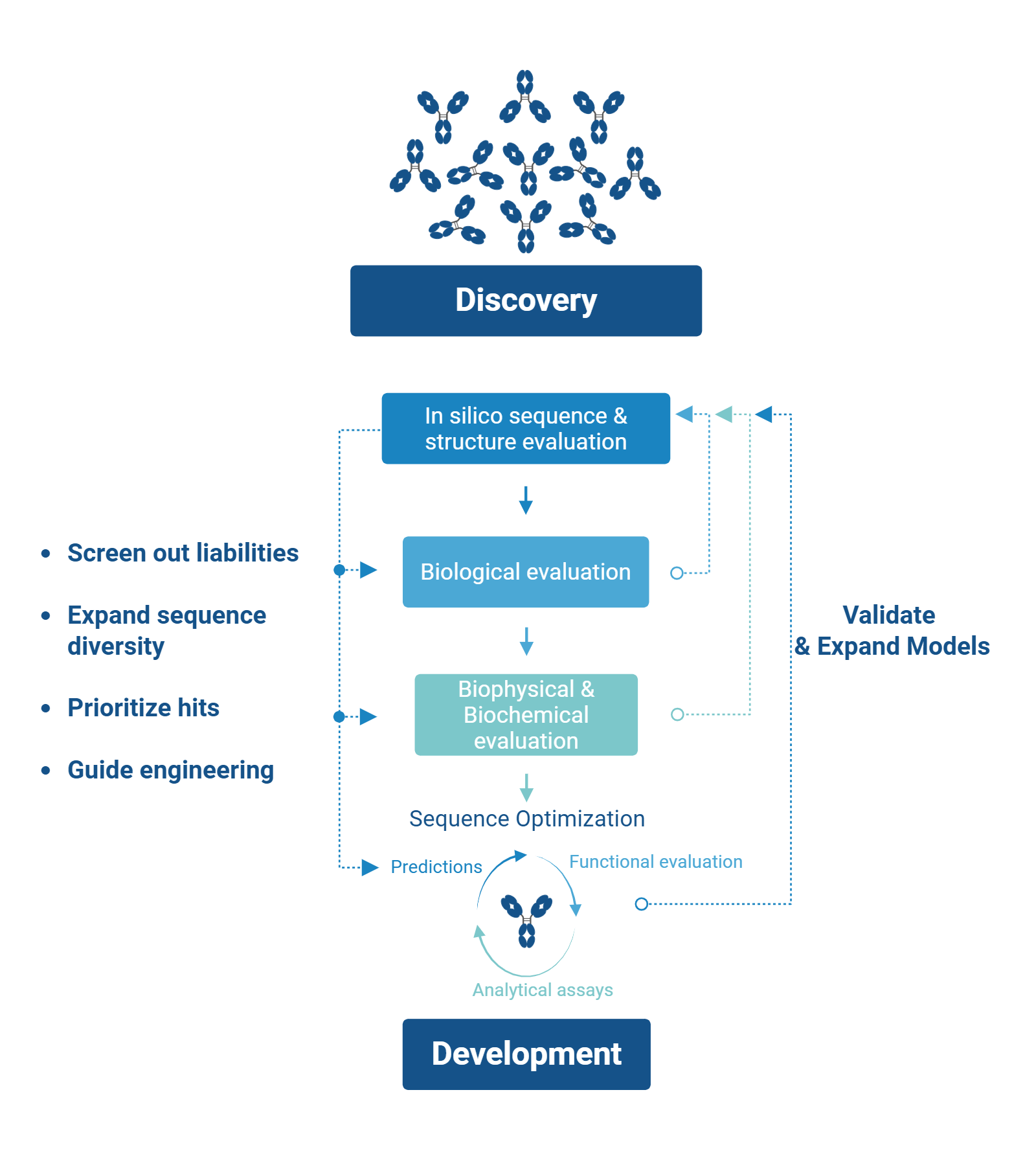
Assessing developability in silico
Among AI applications in antibody discovery, developability prediction offers particularly high downstream impact because it directly targets the biophysical and manufacturability risks responsible for many late-stage failures. Models trained on large datasets linking sequence and structure to experimental outcomes can predict many liabilities before extensive wet‑lab screening begins [7].
Computational and AI-Based Antibody Developability Assessment from Sequence and Structure
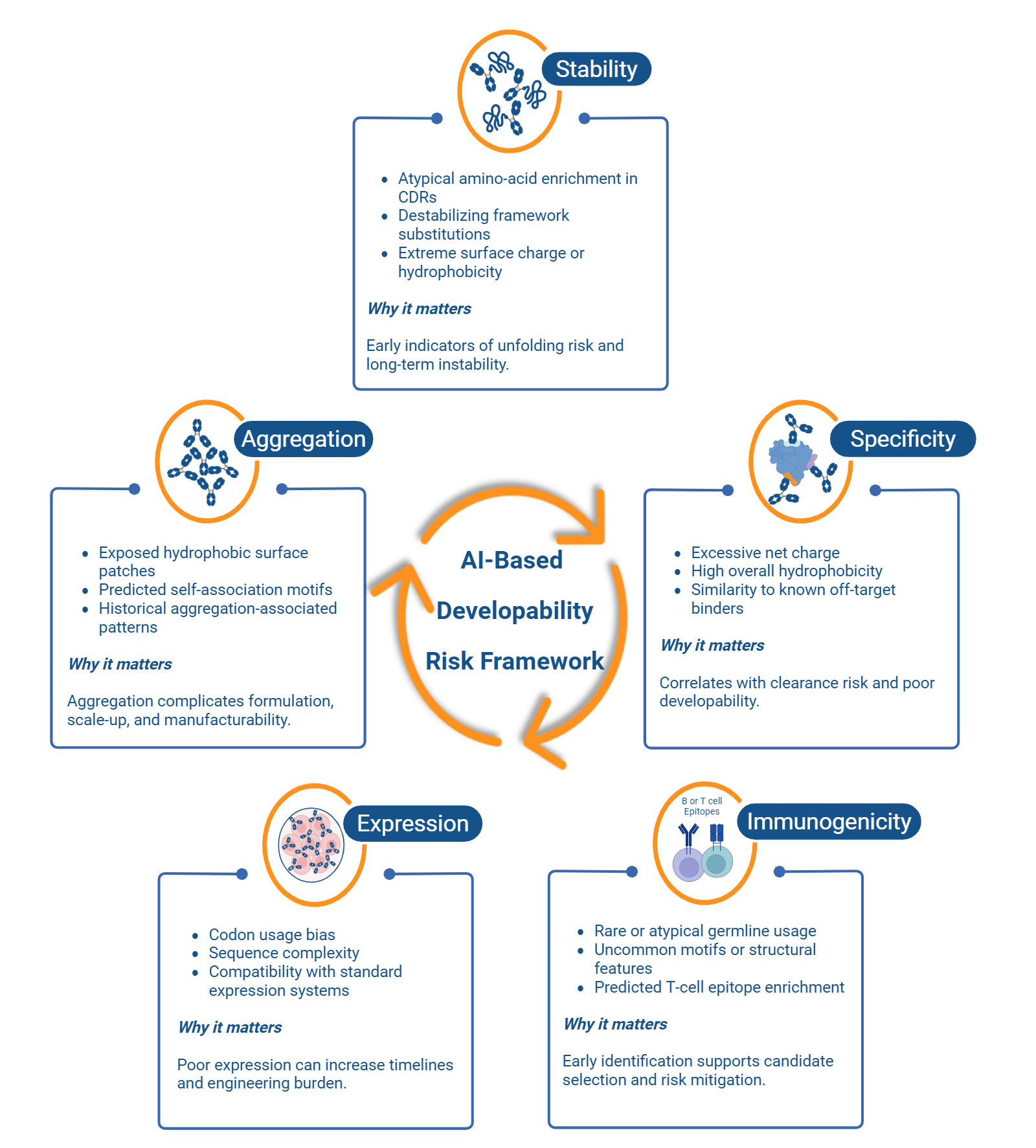
When deployed as decision-support tools rather than replacements for experimental validation, AI-based developability models allow discovery teams to focus resources on candidates that combine strong biological activity with a higher likelihood of downstream success. Their utility depends on careful benchmarking against high quality experimental data and continuous calibration through iterative feedback [6, 8].
AI-Integrated Antibody Discovery at Nona Biosciences
What is HumAtrIx™?
Hu-mAtrIx™ is Nona Bioscience’s proprietary AI platform designed to support antibody discovery and early optimization within Harbour Mice®-based programs (i.e., fully human H2L2 and HCAb generating Harbour Mice). Rather than replacing established and clinically proven discovery workflows, Hu-mAtrIx™ functions as an integrated analytical layer, applying data-driven insights at key decision points to support candidate selection, prioritization, and risk mitigation. By embedding AI directly into in vivo discovery programs, Hu-mAtrIx™ ensures that predictive insights remain anchored in clinically relevant, experimentally validated antibody repertoires. This integration preserves biological diversity while improving the efficiency and consistency of early-stage decision making.
Data Foundation
The predictive performance of Hu-mAtrIx™ is driven by a combination of proprietary and public datasets, including:
- Large-scale, fully human HCAb antibody libraries comprising millions of sequences
- Public protein and antibody sequence datasets spanning tens of millions of entries
- Target-specific binding and functional data generated directly from H2L2 and HCAb Harbour Mice® discovery campaigns
Together, these data enable Hu-mAtrIx™ to capture both broad sequence-level patterns and target-specific binding characteristics, supporting robust prediction across diverse discovery programs.
Integrated Capabilities
Hu-mAtrIx™ incorporates multiple AI-driven analytical modules applied across early discovery and optimization, rather than relying on a single predictive function.
Hu-mAtrIx™ Integration within the Harbour Mice® Antibody Discovery Workflow
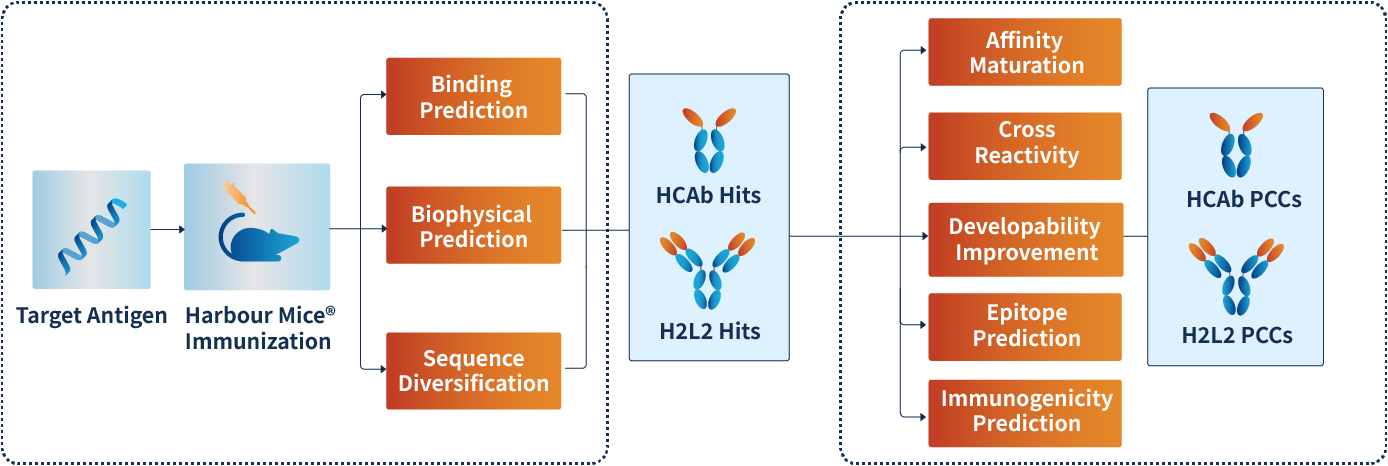
Guided lead prioritization
Machine-learning models support ranking and prioritization of antibody sequences based on predicted binding potential, diversity, and early biophysical indicators such as self-interaction, aggregation tendency, and thermal or colloidal stability.
Predictive affinity assessment
Sequence-based models provide early insight into relative binding performance, helping Nona’s team determine which candidates to advance, deprioritize, or engineer before committing to resource-intensive experimental optimization.
Developability and risk prediction
AI models within Hu-mAtrIx™ assess key developability attributes, including molecular stability, specificity, and immunogenicity risk. Early identification of these liabilities allows for targeted mitigation before candidates enter advanced optimization or IND-enabling workflows.
Sequence diversification
Hu-mAtrIx™ also incorporates generative protein language models to support sequence diversification alongside in vivo discovery. These models are designed to expand biologically relevant sequence space while remaining tightly coupled to experimentally validated repertoires and wet-lab feedback. Generated sequences serve as exploratory inputs rather than replacements for empirical discovery.
Placement within Nona’s discovery workflow
Hu-mAtrIx™ contributes AI-driven insights at multiple stages of antibody discovery:
- In parallel with NGS, expanding discovery space using data from prior Harbour Mice® campaigns
- During post-NGS candidate triage, enabling efficient prioritization of large sequence pools
- At hit-to-lead transition points, informing advancement decisions
- During early optimization, guiding affinity and developability tradeoffs before extensive wet-lab investment
At each stage, the platform is designed to reduce experimental burden while improving the quality and consistency of advancement decisions.

